Learning to walk using reinforcement learning

Intro
Walking is a very basic and indispensable action that is embedded in our daily life. We need to walk to traverse from one place to another. Although it seems to be obvious and too simple, its importance and the level of complexity is taken for granted quite often.
But the same cannot be said in the case of a walking robot. There are lots of physical constraints associated with the model and the environment the robot interacts with. This requires complex levels of control theory and accurate mathematical computations. But there's an alternative solution to the problem of bipedal walking robot - Reinforcement Learning.
History - a research survey
While working at the Computational Intelligence Laboratory, at the Aerospace Engineering Division, IISc, I and my colleague Arun Kumar decided to explore the domain of machine learning for applications related to robotics. We were fascinated by the problem of bipedal walking robots and the challenges associated with it's dynamics and stability.
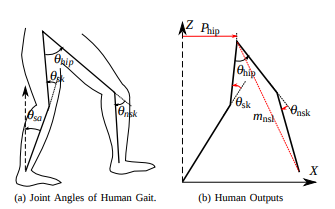
Our initial approaches were inclined towards the classical approach of canonical walking functions, particularly inspired by the works of Dr. Aron D Ames and his team at Georgia Tech & AMBER Lab at Caltech, related to human inspired walking frameworks for bipedal walking robots. Canonical walking functions are based on the human gait outputs such as knee & hip joint angles and horizontal distance of the hip during the gait, to formulate the controllers for the robot.
We also decided to delve more into biologically inspired controllers and came across CPG, acronym for Central Pattern Generators. So what's a CPG?. Basically they are biological neuronal circuits that produce rhythmic outputs (even in the absense of rhythmic input or sensory feedback). They are the source of the tightly-coupled patterns of neural activity that drive rhythmic motions, for example walking
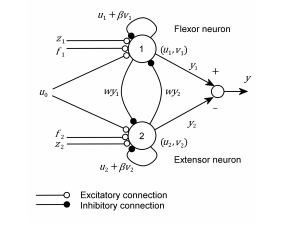
We were heavily influenced by the work of Atılım Güneş Baydin on "Evolution of central pattern generators for the control of a five-link bipedal walking mechanism". On a brief note, this paper describes the approach of determining the connectivity and oscillatory parameters of a CPG network through genetic algorithm(GA) optimization techniques. The CPG model adopted is that of a Matsuoka's half-center oscillator model shown here.
Reinforcement learning approach.
Humans rely on learning from interaction, repeated trial and errors with small variations and finding out what works and what not. Let’s consider an example of a child learning to walk. It tries out various possible movements. It may take several days before it stands stably on its feet let alone walking. In the process of learning to walk, the child is punished by falling and rewarded for moving forward.

This rewarding system is inherently built into human beings that motivate us to do actions that garner positive rewards (e.g.,happiness) and discourage the actions that account for bad rewards(e.g.,falling, getting hurt, pain, etc.). This kind of reward based learning has been modelled mathematically and is called Reinforcement learning. A typical reinforcement learning setting consists of an agent interacting with the environment E. After each time step t, the agent receives an observation st from the environment and takes action at for which it recieves a scalar reward rt & next state st+1 as seen in figure below.

Fig.3 Agent-environment interaction in RL setting.
Deep Determinsitic Policy Gradient.
In 2016, researchers from Google DeepMind, London, published their results related to "Continuos Control with Deep Reinforcement Learning" in ICLR. The learning framework is based on the actor-critic network

Fig.4 Actor-Critic network.
Initial learning phase.
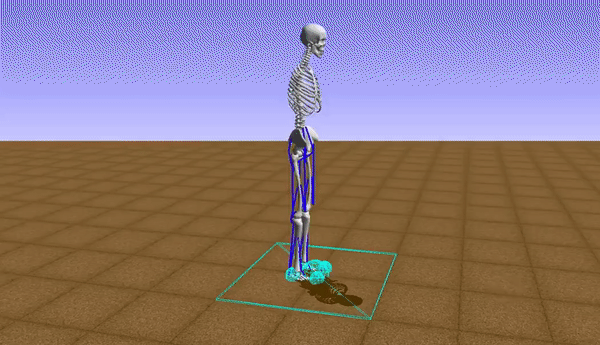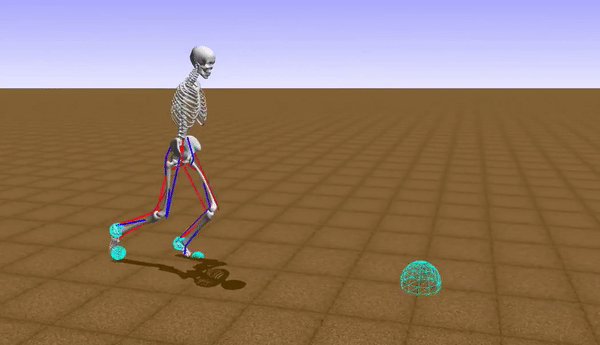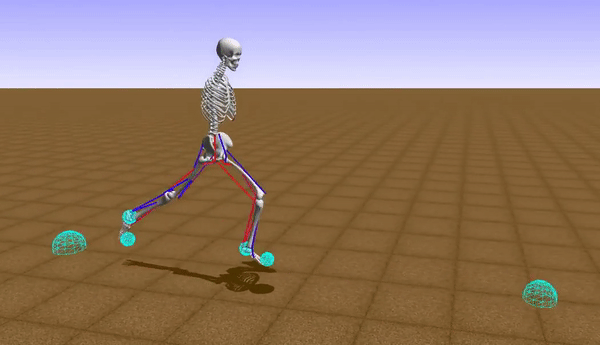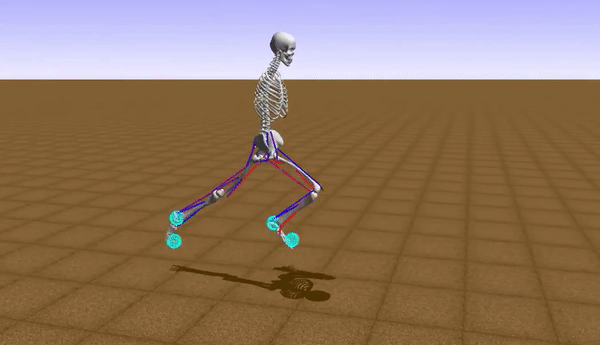
At the initial stages of the learning to walk, the robot takes baby steps and eventually fails a lot of times by falling down. The reward function is modelled accordingly by this inference so that the robot moves forward while maintaining constant waist-height from the ground to maximize the reward for each iteration.

Results & comparison with an actual human gait.
Our model learned to generate a stable walking gait after roughly over 41 hours of training (using a Nvidia GeForce GTX 1050 Ti GPU). After training the model in simulation, it was observed that, with a proper shaped reward function, the robot achieved faster walking (or even rendered a running gait) with an average speed of 0.83 m/s. Though the problem of convergence of the learning still persists with the DDPG algorithm, we were able to get a bipedal gait which was similar to that of a human's. The human gait was synthezised & derived using optical motion capture camera setup at the Advanced Flight Simulation Laboratory, Dept. of Aerospace Engineering, IISc. The half-body marker placement convention was adopted while recording the subject's walking gait. The hip & knee joint rotations of the human subject and the bipedal walker were gathered and the subsequent plots were generated, depicting similarities in patterns.


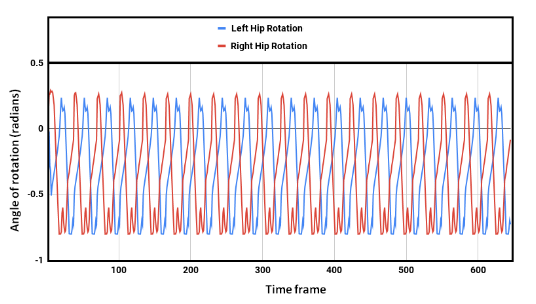
Fig.8 Hip joint rotation trajectory for biped robot.
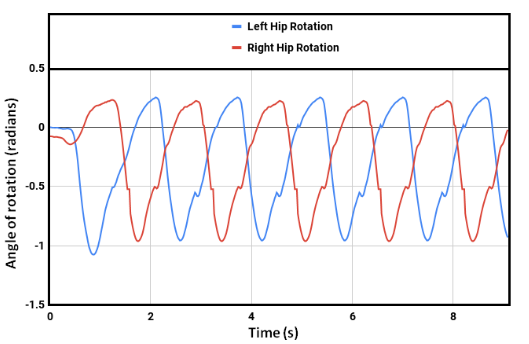
Fig.9 Hip joint rotation trajectory for human walking.
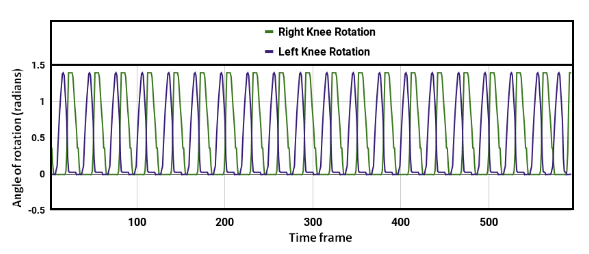
Fig.10 Knee joint rotation trajectory for biped robot.
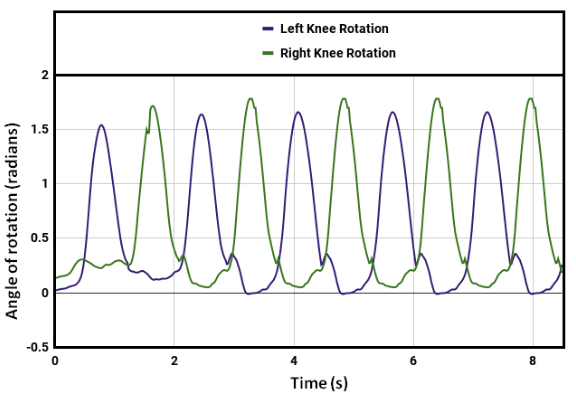
Fig.11 Hip joint rotation trajectory for human walking.
Research outputs & future works
[1] The research manuscript detailing our reinforcement learning approach for bipedal walking robot & corresponding results have been documented and can be accessed here: Kumar, Arun, Navneet Paul, and S. N. Omkar. "Bipedal Walking Robot using Deep Deterministic Policy Gradient." arXiv:1807.05924 (2018).
[2] Simulation framework (using ROS & Gazebo) for the planar bipedal walking robot is opensourced through GitHub here. You can explore the recent state of the art RL algorithms such as PPO or TRPO for generating walking patterns for the biped robot.
Other useful resources:
There are several similar opensource resources available online which use machine learning techniques for training an agent to walk (or possibily, even run). I have made a mention of a few below.
[1] NeurIPS "Learning to run" challenge: Over the past two years NeurIPS, [formerly known as NIPS] has been hosting the online "Learning to run" challenge, where the contestents have to train a musculoskeletal model in Opensim simulation environment to run at a particular speed and avoid obstacles at the same time.[NeurIPS, 2018 challenge][repository]